I’ve been diving pretty deep into DuckDB. It has shown that it has great utility for the vast majority of mid to large scale data analysis tasks—I’m talking Gigabytes not Petabytes. In particular, Kirill Müller of Cynkra, has been doing great work in bringing DuckDB to the R community.
I think the R community would benefit greatly by adopting DuckDB into their analytic workflows. It can used to make highly performant shiny applications or just speed up your workflow.
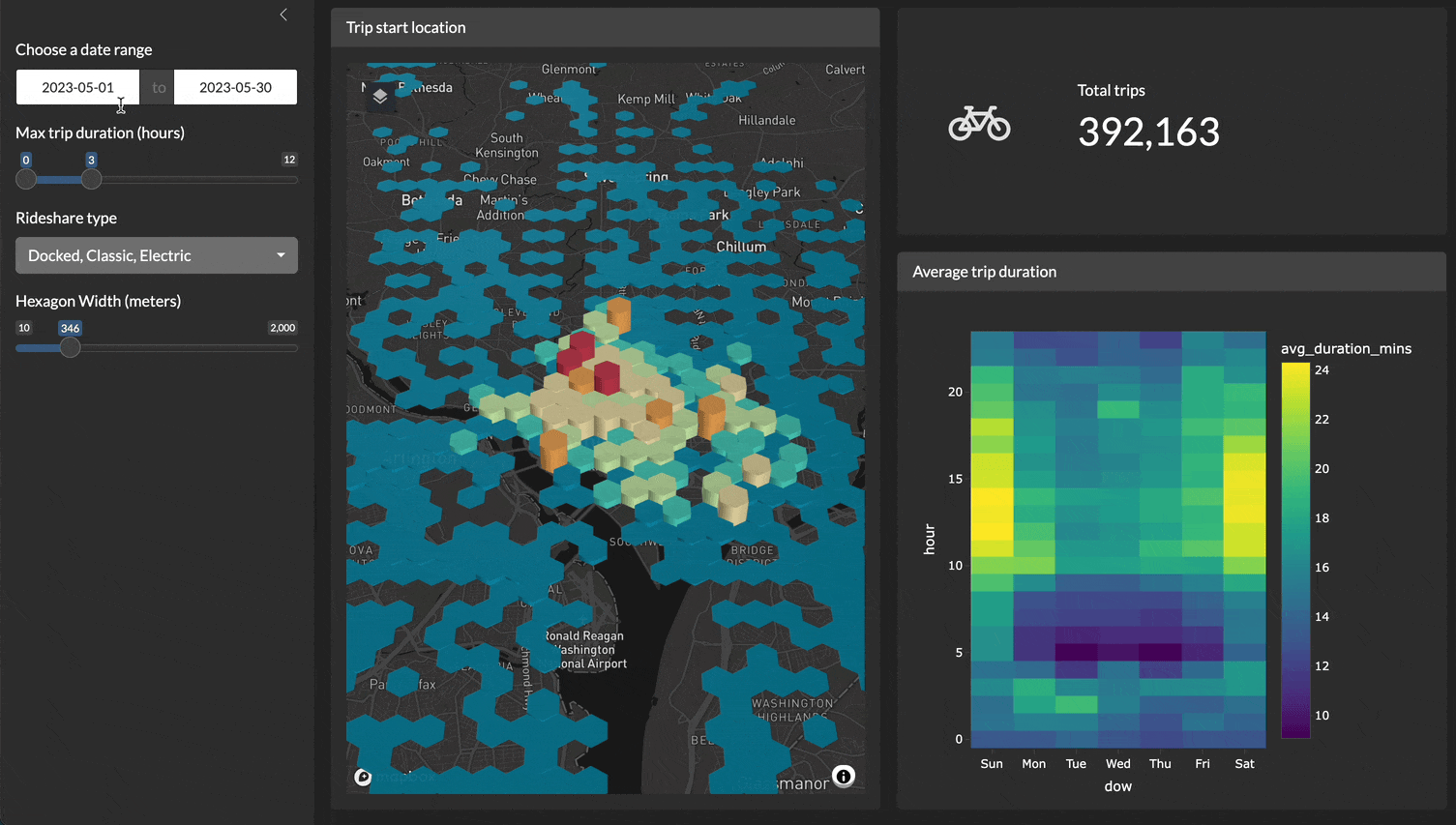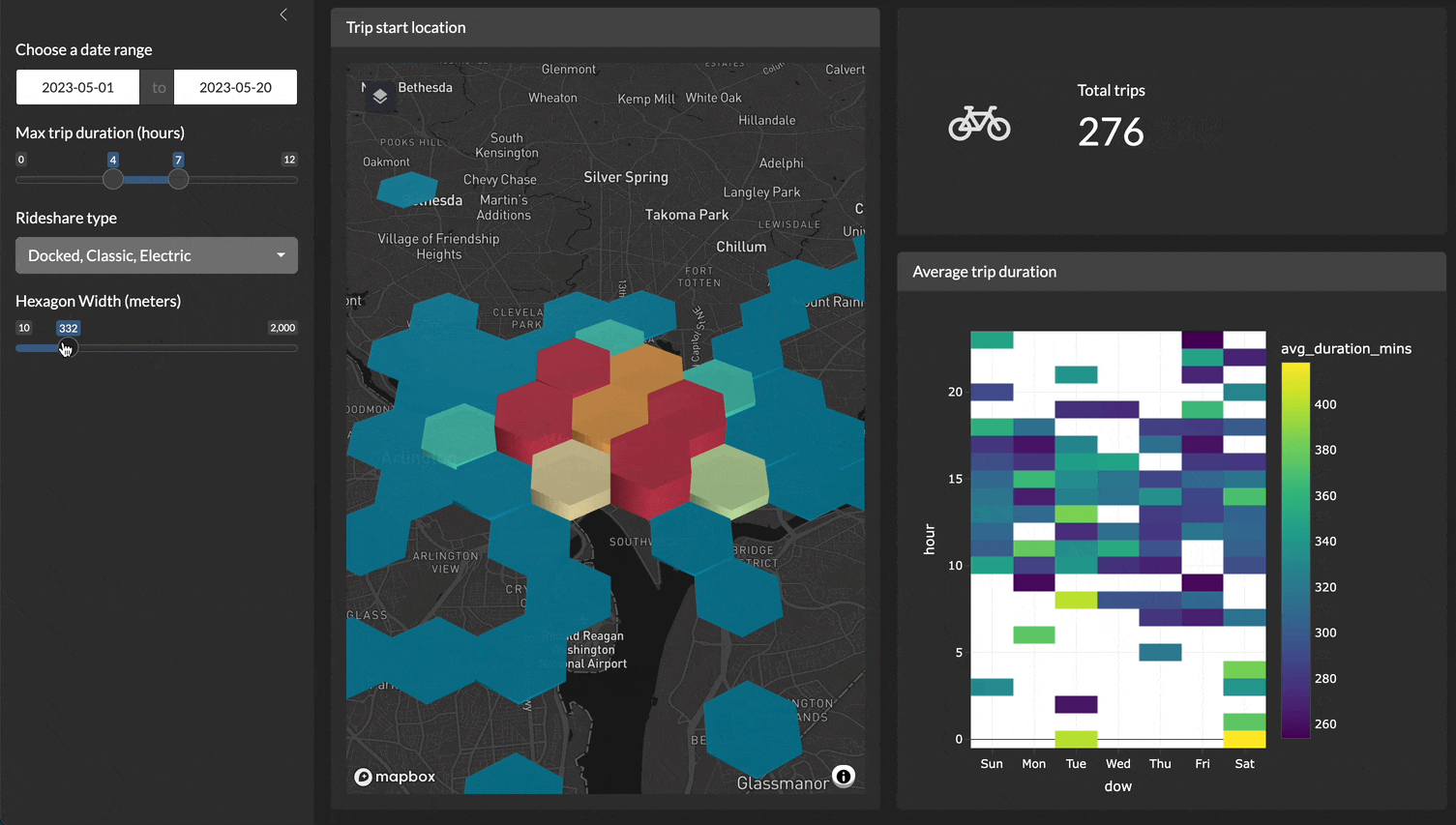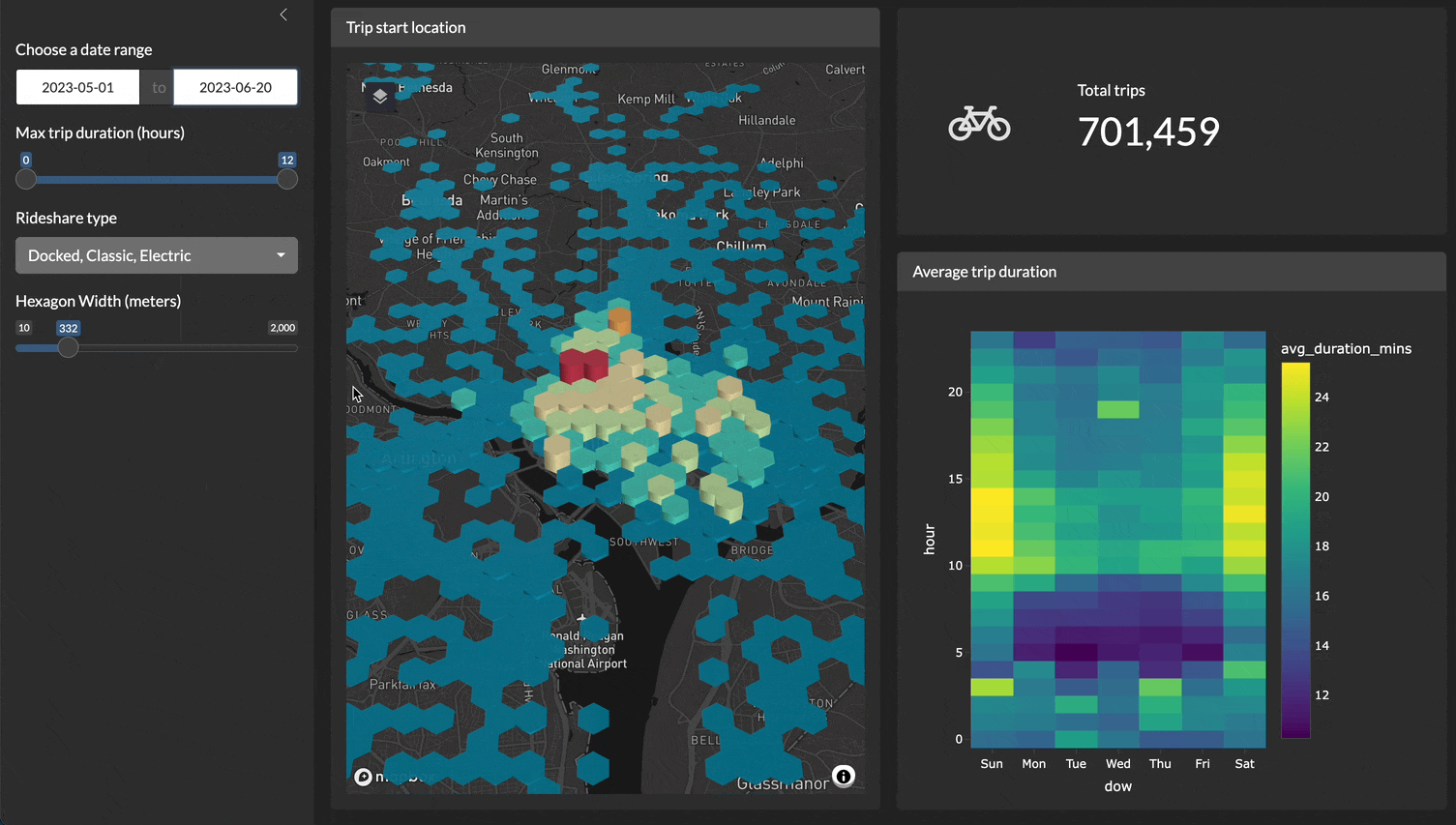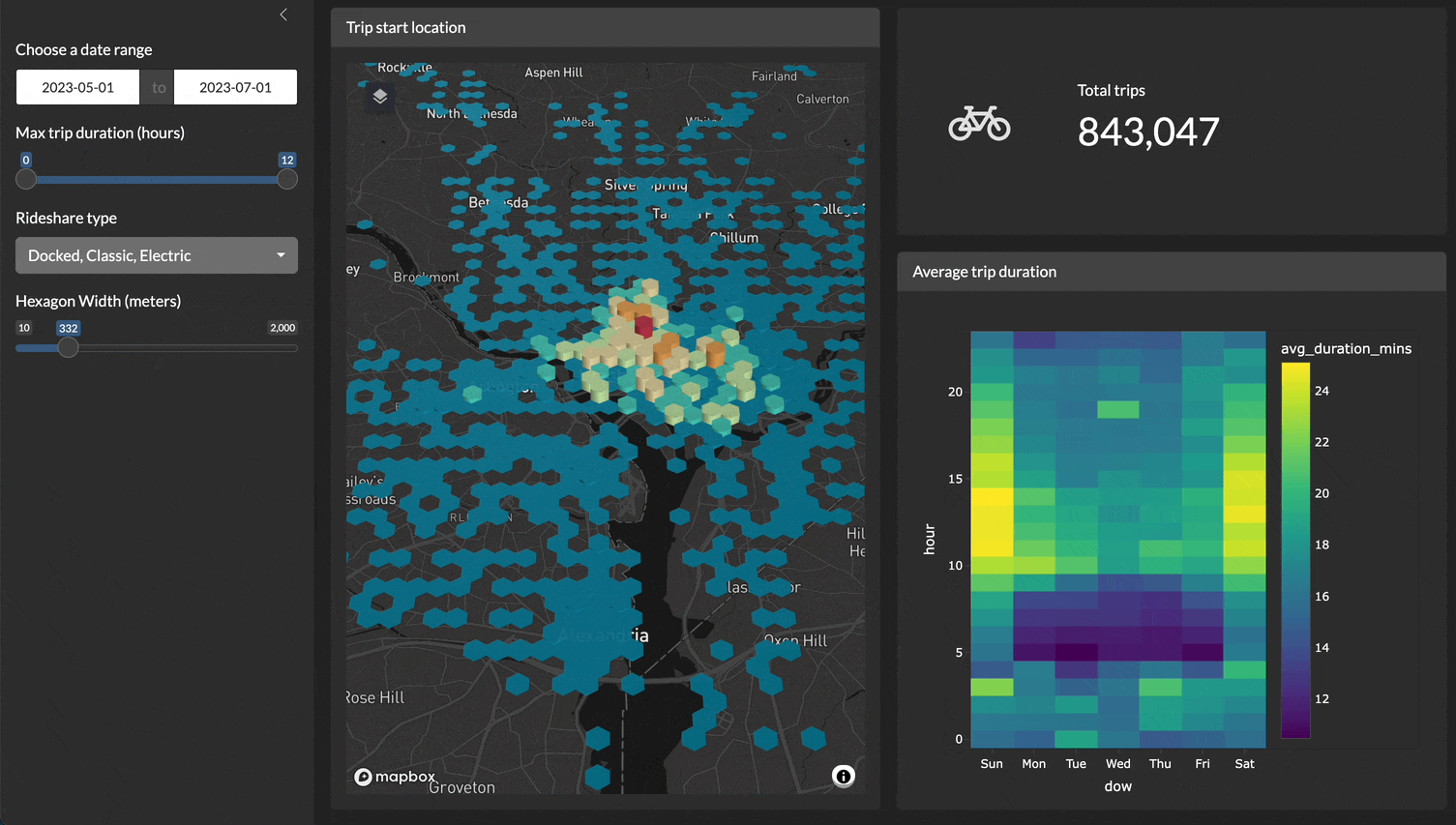
For example, here is a demo of a Shiny application filtering, plotting, and visualizing 4.5 million records very quickly!
a personal note
I’m beginning to build out some content for courses that I’ll be making availble through my new website flrsh.dev (pronounced flourish). Sign up if you want to be notified when we start rolling things out 🙃.
The first course will be on DuckDB!
Also, if it takes a while to load, thats because the provider is spinning up an instance because no one is on it lol! It is very much a WIP.
Y’all keep asking me {duckdb} or {duckplyr}
and before I tell you what my answer is, I’ll tell you why I’m bullish on DuckDB. I won’t ramble on details.
Jargon giraffe 🦒: bullish!
Bullish is a term that is associated with a growing stock market. Think of the upward motion of their horns. People who are “bullish” would spend more money in the stock market expecting its prices to continue to rise and thus make more moneyyy 💸💸💸
Why DuckDB?
Supports larger-than-memory workloads
Columnar vectorized operations means operating only on the data you need to and more of it and faster!
Supports Substrait for database agnostic query plans
Runs in the browser (think ShinyLive + DuckDB means fast compute all running in the browser without a Shiny server)
_ It is stupid fast_
My verdict?
The thing that is most important, in my opinion, for DuckDBs ability to be useful to the R community is its ability to work on data that is larger than RAM. Read this awesome blog post.
The R package duckplyr is a drop in replacement for dplyr. duckplyr operates only on data.frame objects and, as of today, only works with in memory data. This means it is limited to the size of your machine’s RAM.
{duckdb}
duckdb, on the other hand, is a {DBI} extension package. This means that you can use DBI functions to write standard SQL. But it also means that you can use use tables in your DuckDB database with dplyr (via dbplyr).
duckdb allows you to write standard dplyr code and create lazy tables that can be combined to make even lazier code! Moreover, you can utilize the out-of-core processing capabilities with DuckDB using duckdb and, to me, that is the whole selling point.
If performance is your objective and you, for some reason, refuse to use the out-of-core capabilities of DuckDB, you should just use data.table via dtplyr.
Getting started with DuckDB & R
Using DuckDB as a database backend for dplyr is pretty much the same as anything other backend you might use. Very similar code to what I’ll show you can be used to run code on Apache Spark or Postgres.
# This uses **in memory** database which is limited by RAMdrv<-duckdb()# this creates a persistent database which allows DuckDB to# perform **larger-than-memory** workloadsdrv<-duckdb(tempfile(fileext =".duckdb"))drv
<SQL>
SELECT houseAge, AVG(houseValue) AS avg_val
FROM (FROM '/var/folders/wd/xq999jjj3bx2w8cpg7lkfxlm0000gn/T//Rtmpt7T0Xr/file84ac12eaa270.csv') q01
GROUP BY houseAge
Bring the results into memory
Use dplyr::collect() to bring the results into memory as an actual tibble!